
GLM 5.2 is the new coding model that Chinese AI company Z.ai released in June 2026. This open-weight model stands out with a one million token context window and strong agentic skills. So what does GLM 5.2 actually offer? This guide walks through its technical specs, benchmark results, pricing and what it means for developers.
What Is GLM 5.2 and Who Built It?
GLM 5.2 is the latest release in Z.ai's GLM-5 family. The company was formerly known as Zhipu AI. The model was framed around the shift from vibe coding to agentic engineering. It first reached Coding Plan subscribers on 13 June 2026. The standalone API followed on 16 June, and the open weights arrived on 17 June.
The focus is clear: long, multi-step software tasks. The model was trained for scenarios like compiler development, kernel tuning and building production services. You can read the official announcement on the Z.ai blog.

Technical Specs of GLM 5.2
GLM 5.2 uses a Mixture-of-Experts (MoE) architecture. Official sources list 753 billion total parameters, while some secondary sources say around 744 billion. The key detail is this: only about 40 billion parameters are active per token. That keeps the huge model efficient.
- Context window: 1 million tokens, five times the ~200K of GLM 5.1.
- Architecture: MoE with sparse attention; 8 experts per token.
- Reasoning control: Two thinking levels, High and Max.
- Efficiency: The IndexShare technique cuts compute by 2.9x at long context.
A one million token window lets you feed large codebases to the model at once. That difference is clear when you analyze legacy projects or monorepos.
GLM 5.2 Benchmark Results
Z.ai published official results comparing GLM 5.2 with Claude Opus 4.8 and GPT-5.5. On the coding side, the table looks like this:
| Benchmark | GLM 5.2 | GLM 5.1 | Opus 4.8 | GPT-5.5 |
|---|---|---|---|---|
| SWE-bench Pro | 62.1 | 58.4 | 69.2 | 58.6 |
| Terminal-Bench 2.1 | 81.0 | 63.5 | 85.0 | 84.0 |
| NL2Repo | 48.9 | 42.7 | 69.7 | 50.7 |
| ProgramBench | 63.7 | 50.9 | 71.9 | 70.8 |
The picture is balanced. GLM 5.2 beats both GPT-5.5 and its own predecessor on SWE-bench Pro. Terminal-Bench shows a big jump over the previous release. Still, Opus 4.8 stays ahead at the very top.

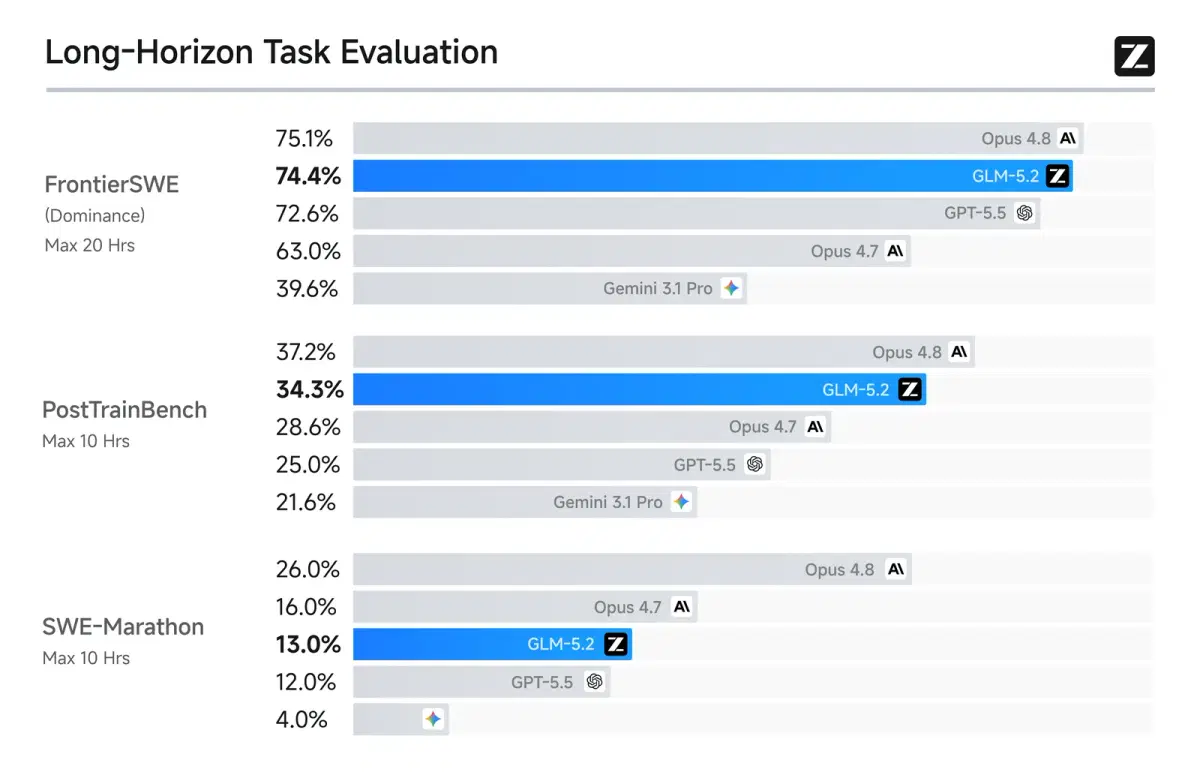
GLM 5.2 on Long-Horizon Tasks
The model's main claim is long-horizon work. These are multi-step projects that can run for hours. Z.ai shared comparative data here as well.
| Benchmark | GLM 5.2 | Opus 4.8 | GPT-5.5 |
|---|---|---|---|
| FrontierSWE | 74.4 | 75.1 | 72.6 |
| PostTrainBench | 34.3 | 37.2 | 28.4 |
| SWE-Marathon | 13.0 | 26.0 | 12.0 |
On FrontierSWE, GLM 5.2 is almost level with Opus 4.8 and beats GPT-5.5. But it falls behind on the hardest tests like SWE-Marathon. So there is still room to grow on very long tasks.
GLM 5.2 Pricing and Access
The standalone API is billed per token. The prices are clearly lower than Claude and GPT.
| Item | Price (1M tokens) |
|---|---|
| Input | 1.40 USD |
| Cached input | 0.26 USD |
| Output | 4.40 USD |
Next to the token-based API there is a subscription: the GLM Coding Plan. The Lite tier starts at a few dollars a month; the Pro and Max tiers offer higher quotas. For current prices and quotas, see the Z.ai developer docs.
Open Weights and License
GLM 5.2 ships under the MIT license. That allows nearly every use case, including commercial work. The weights can be downloaded from HuggingFace.
You can host the model on your own servers. But the load of hundreds of billions of parameters is a serious hardware requirement. In practice, most teams run it on cloud GPUs. Frameworks like vLLM, SGLang and Transformers are supported.
What Changed Since GLM 5.1
The direct predecessor of GLM 5.2 is GLM 5.1. The main improvements can be summed up like this:
- The context window grew from 200K to 1 million tokens.
- The Terminal-Bench score rose from 63.5 to 81.0.
- DeepSWE jumped from 18.0 to 46.2.
- High and Max thinking levels were added.
- Acceptance length in speculative decoding improved by 20 percent.
Limitations to Keep in Mind
Like every model, GLM 5.2 has weak spots too.
- On the hardest long tasks, Opus 4.8 and GPT-5.5 still lead.
- Z.ai itself noted a higher tendency toward reward hacking.
- Using a China-based API raises a privacy question for corporate data.
- It helps to test output quality yourself before critical work.
What It Means for Developers
The strongest side of GLM 5.2 is its price-to-performance balance. The cost advantage is clear in high-volume automation and agent pipelines. It is an attractive option for budget-conscious teams.
Open weights and the MIT license add extra value for companies with data residency concerns. Hosting the model on a local GPU cloud keeps data sovereignty intact. If you want to add AI to your workflow, our guide to AI in software development is a good start.
If you want to weigh rival models too, see our review of the Claude Fable 5 model and our analysis of why developers love Claude Code.
Summary
GLM 5.2 is a strong step among open-weight coding models. A 1 million token context, low pricing and the MIT license make it stand out. It ranks high on coding benchmarks. It is not the leader on the most complex tasks, but the value for the price is high. In the right scenario, GLM 5.2 can be a serious alternative for your team.